This article describes how to force manual failover of AlwaysOn Group. A forced failover is a type of manual failover that is strictly for disaster recovery scenarios. Important to realize, in such scenario a planned manual failover is not possible.
Problem:
For example you have a SQL Server Availability Group (AG) on a Windows Server Failover Cluster (WSFC) with two nodes. Imagine a situation when one node is completely offline\unavailable or AG Group resource is offline in cluster.
This may cause the AG Group to go into a Resolving state and all the databases in the AG and the Listener will be inaccessible.
Now you must restore the service. In this scenario you have to do force failover and willing to risk losing data.
Solution:
First bring up the WSFC using the forced quorum method. Second Force Failover AG with allow data loss option.
For Example SQLP1 (Primary) is unavailable. WSFC is down and AG is inaccessible.
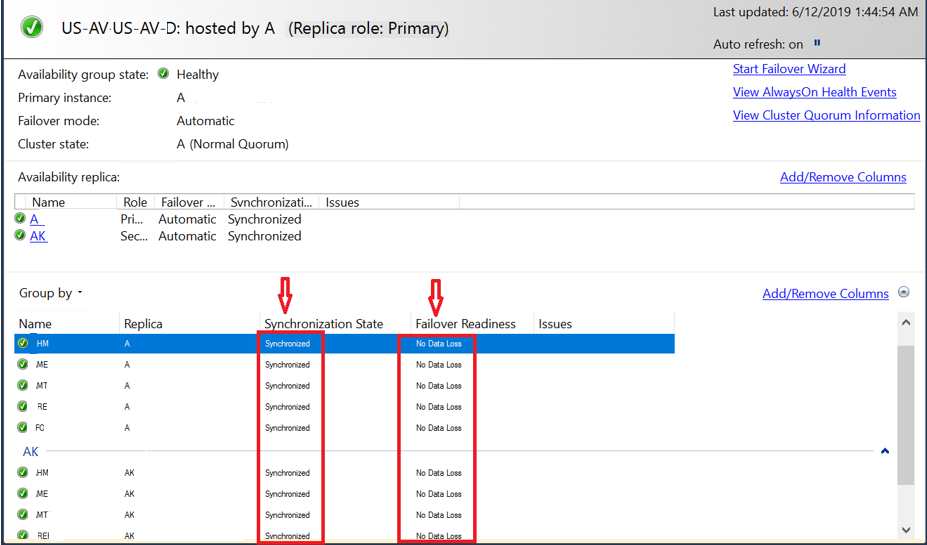
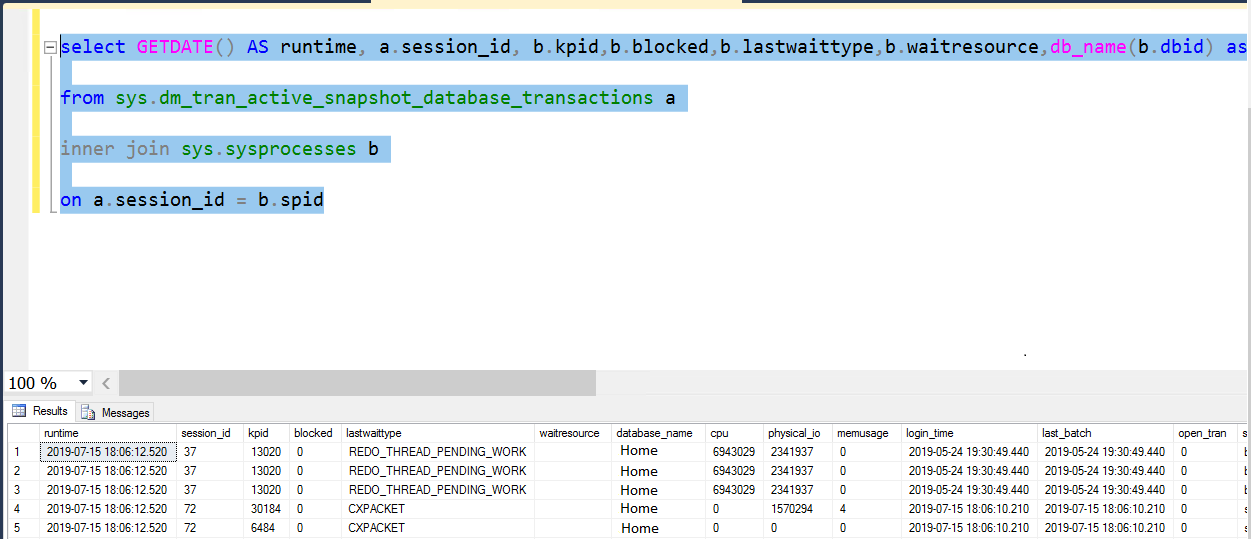
SQLP2 (Replica) is up and running, and you can connect to SQLP2 from SSMS. The Always On Dashboard lists SQLP2 in the Availability replica, showing AG Group in Resolving state.
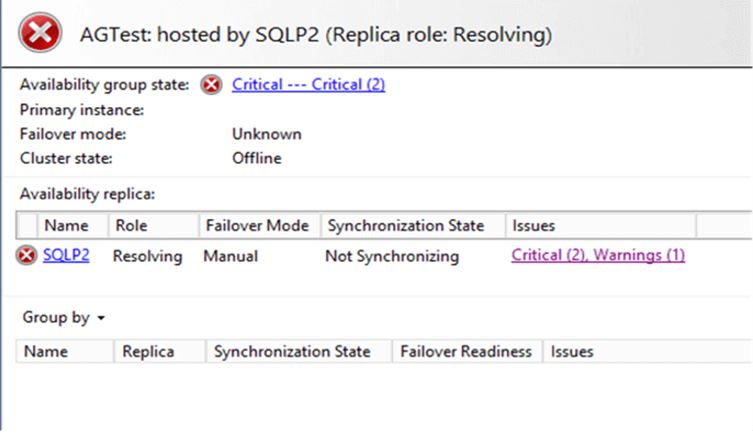
Recover WSFC using Force Quorum
Important to realize that this is actually forcing a cluster to start without a quorum. Again there are two ways of achieving this. Using powershell and command prompt.
Fix Quorum Using PowerShell:
Start PowerShell using Run As Administrator. You can refer the article Powershell Script to Create Folders where I had shown this step.
Import-Module FailoverClusters $node = "SQLP2" Stop-ClusterNode -Name $node Start-ClusterNode -Name $node -FixQuorum (Get-ClusterNode $node).NodeWeight = 1
Force Quorum Using Command Prompt:
Open command prompt using Run As Administrator. In the first place bring down the cluster service on SQLP2.
C:\>Net stop clussvc

Now bring up Cluster Service with Force Quorum
C:\>Net start clussvc /forcequorum

At this moment if you launch WSFC manager, the quorum will show warning as shown in the below screen shot.
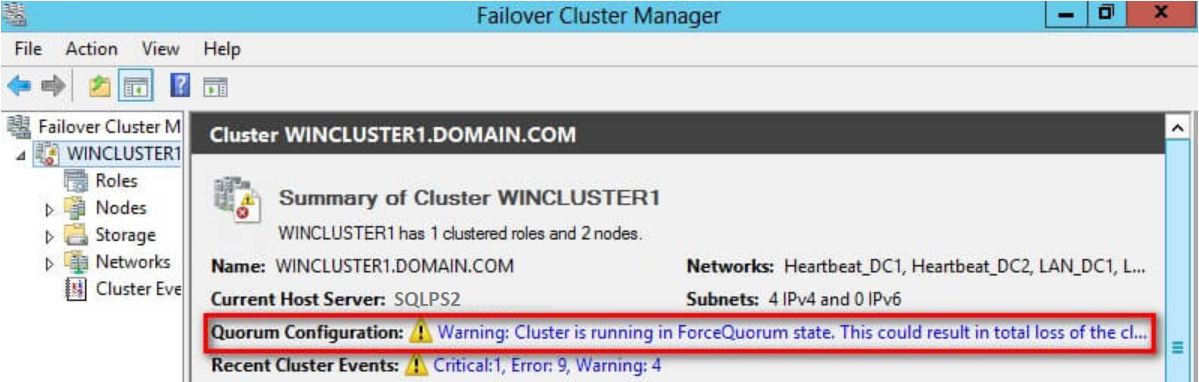
Now the second part of the solution.
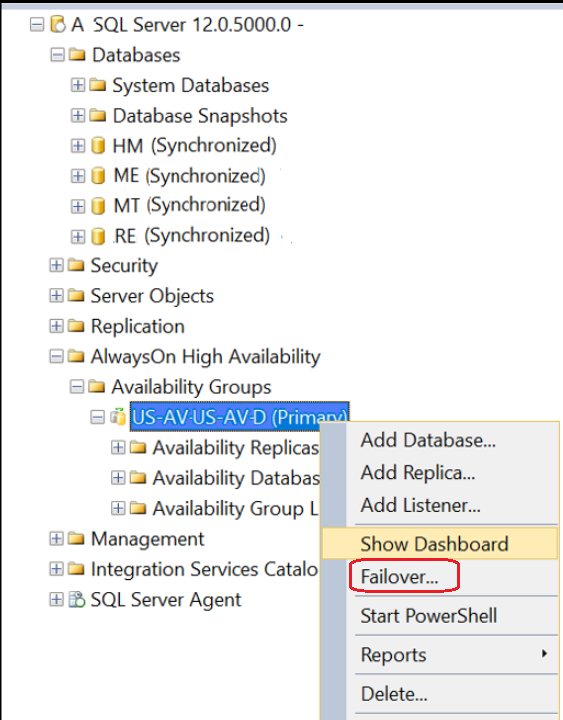
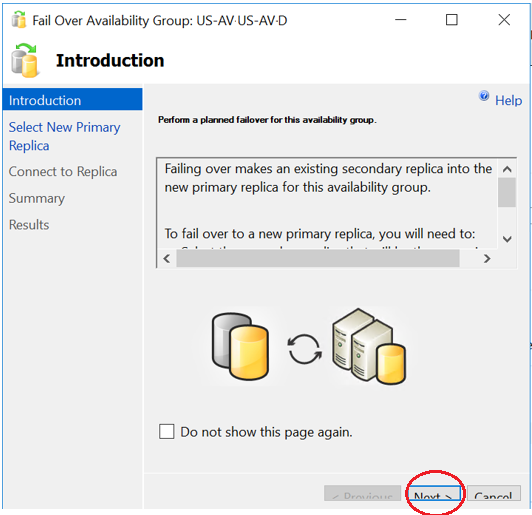
Force Always On Failover with Allow data loss:
Now since WSFC is up, the user databases in the AG will appear in the AG Dashboard, but they will be in the Not Synchronizing State.
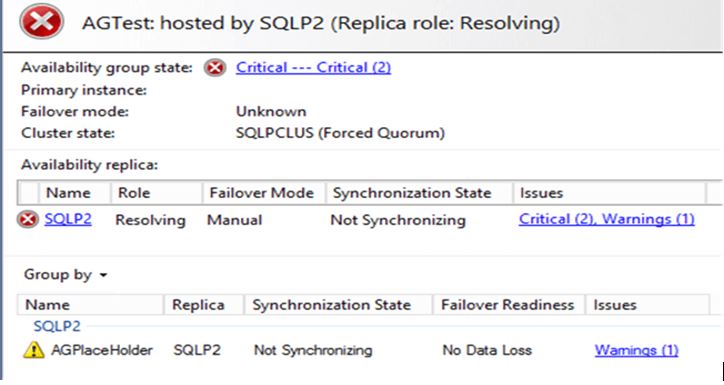
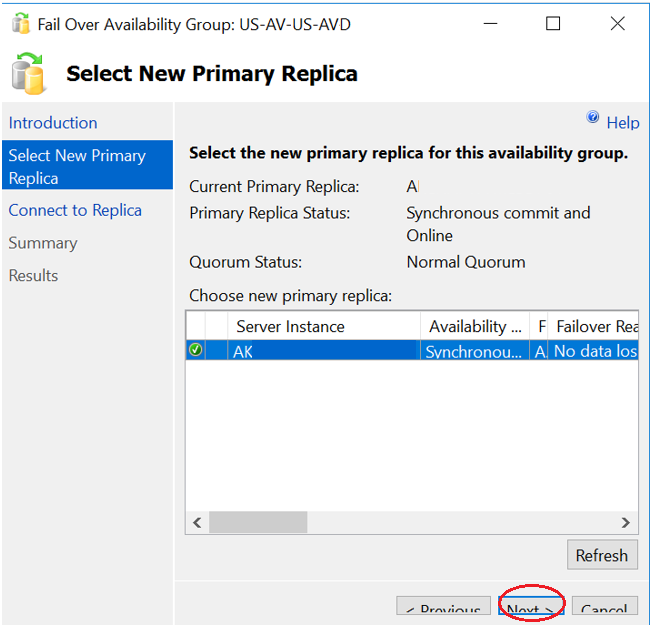
We will need to perform a forced AG failover to the SQL Server replica which is still up and running using with allow data loss option. In our example the replica to which we’ll do force failover is SQLP2.
The T-SQL Command to force failover is as follows:
ALTER AVAILABILITY GROUP AGTest FORCE_FAILOVER_ALLOW_DATA_LOSS;
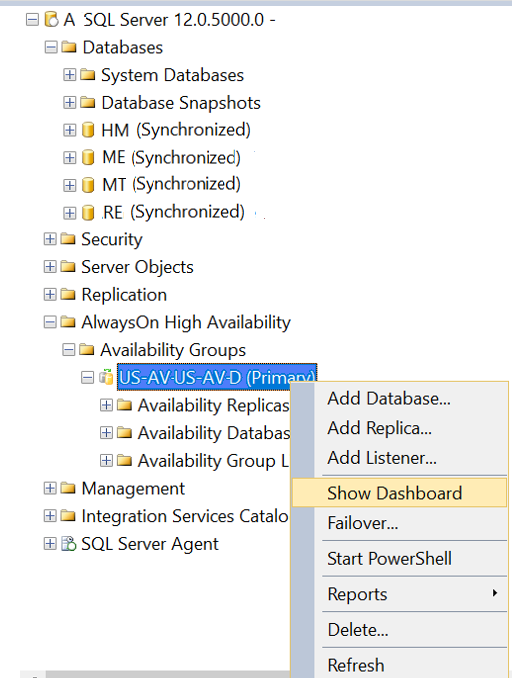
At this moment the AG should be up and running. Open the AlwaysON Dashboard again and it should now show SQLP2 as Primary and running. This will allow applications to connect to the AG listener and the service is restored.
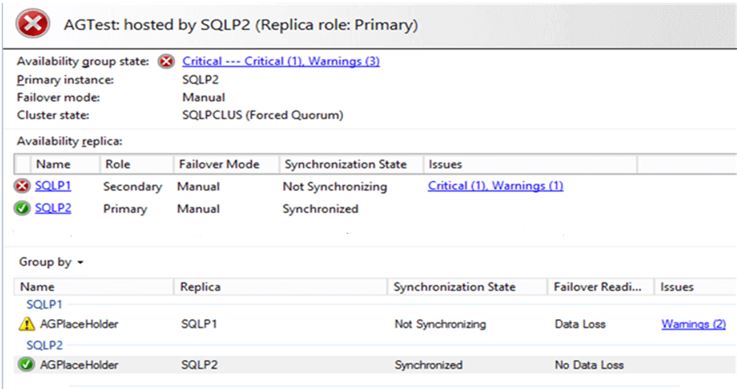
When the issue with the server SQLP1 is fixed, they will re-join the WSFC automatically. As long as AG is not removed from other SQL Server instances, they will be able to re-join into the AG as well.
After a forced failover, all secondary databases are suspended. This includes the former primary databases, after the former primary replica comes back online and discovers that it is now a secondary replica. You must manually resume each suspended database individually on each secondary replica.
Resuming of data movement using SSMS:
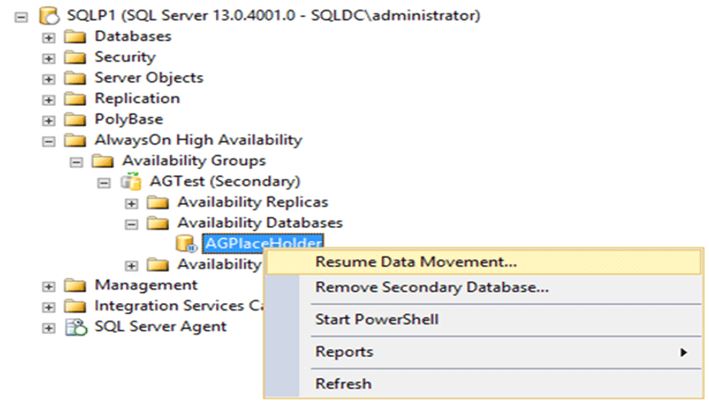
T-SQL to resume data movement for the AG:
ALTER DATABASE [AGplaceHolder] SET HADR RESUME; GO
Summary:
Here we have described a situation when only one node was up in a WSFC without quorum. We performed force quorum to bring up WSFC on a single node (available replica) and brought the SQL AlwaysOn Group back to functional. Once the problem node came up, we resumed data movement to sync the availability databases.
Hope this helps. Please feel free to comment in case of any questions.
You may also interested in the following articles:
How SQL Agent Job Schedule Got Changed Automatically
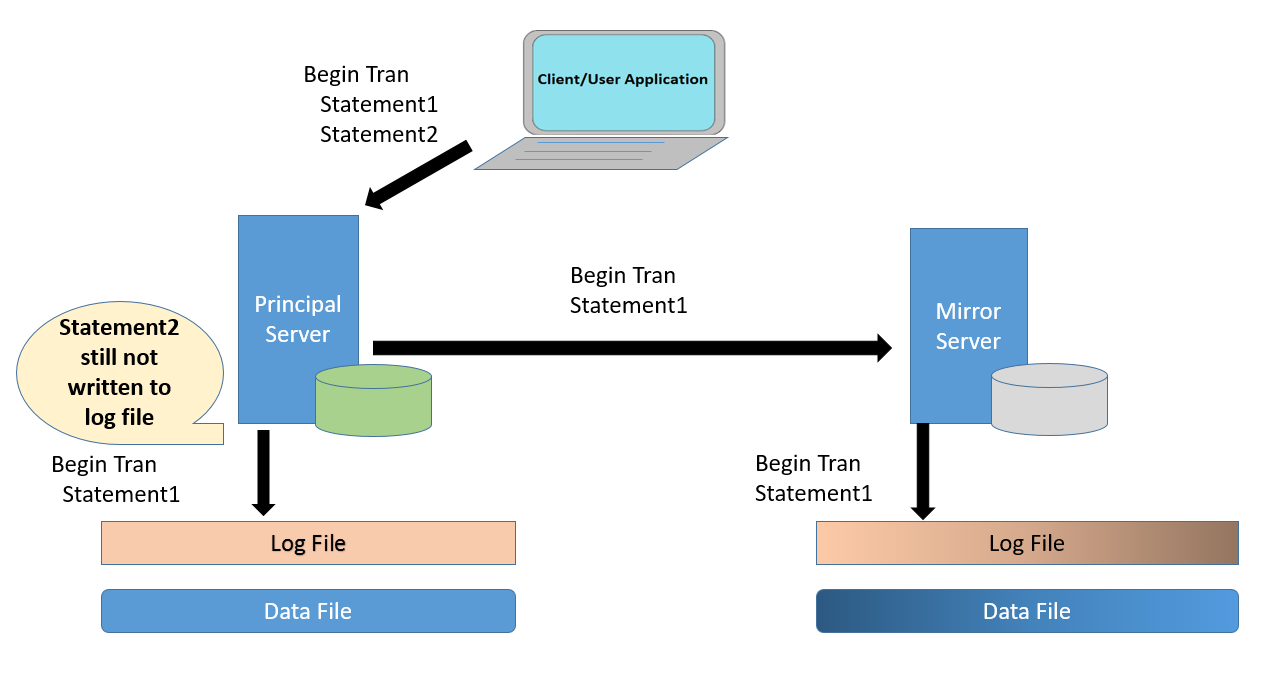
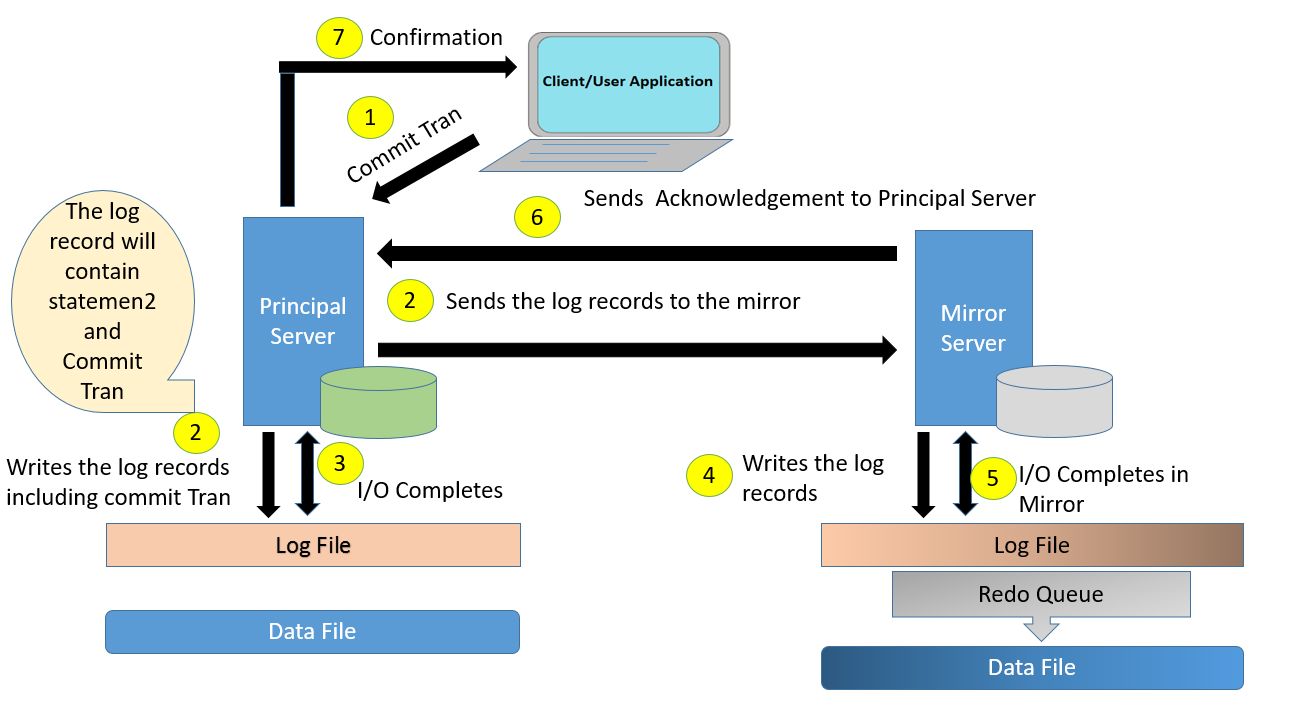
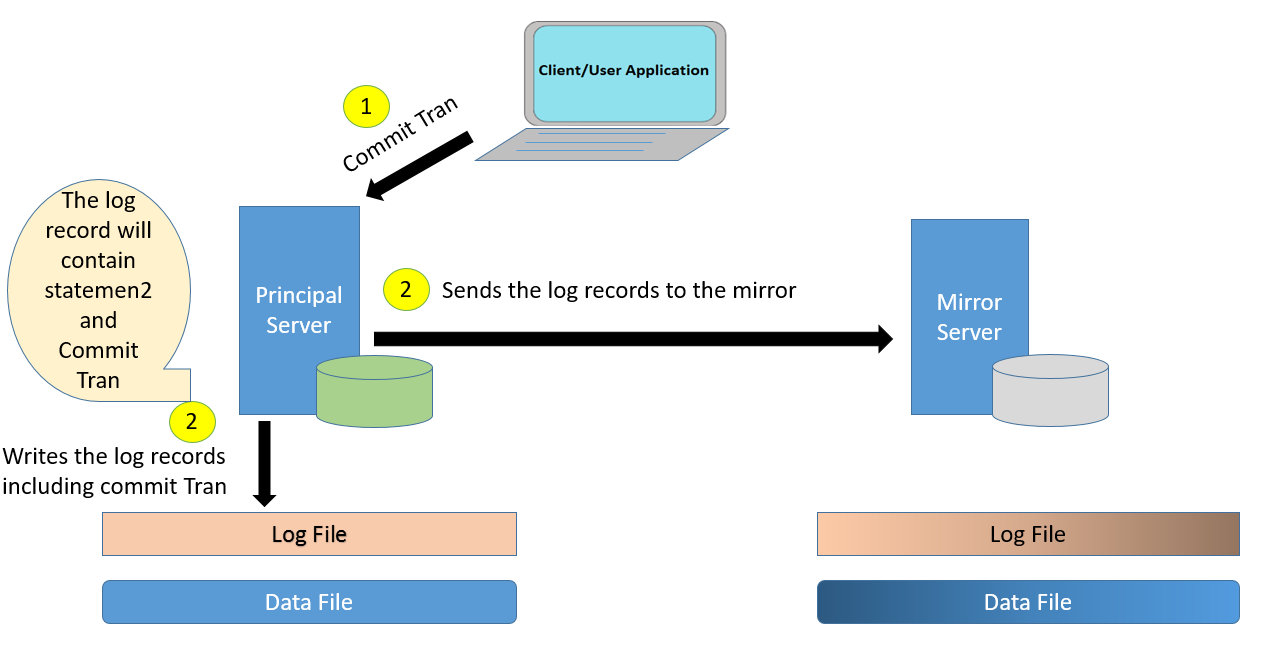 Note: Principal Server has written the log records to the log file. So one of the misconception is cleared here. Principal Server does not wait for acknowledgement from mirror to commit the transaction.
Note: Principal Server has written the log records to the log file. So one of the misconception is cleared here. Principal Server does not wait for acknowledgement from mirror to commit the transaction.