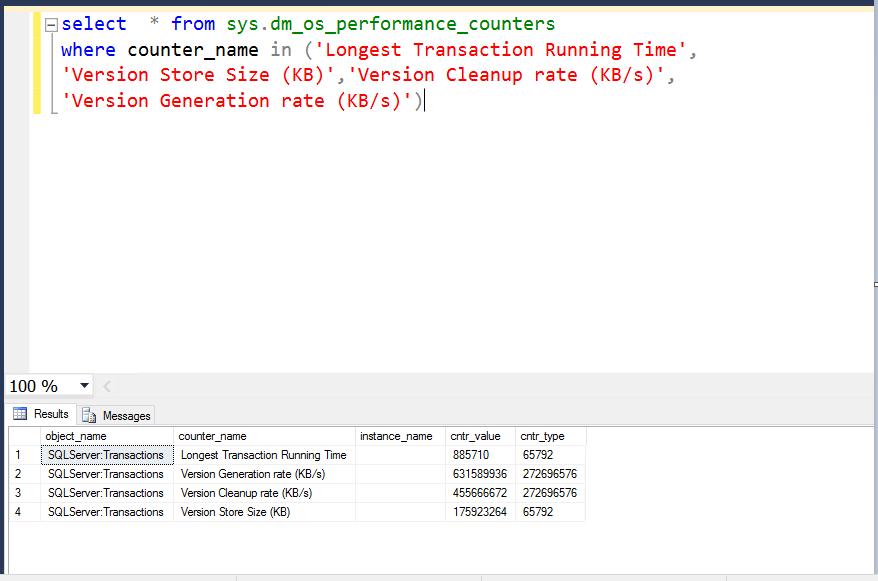
This article is about detailed Steps in SQL Server Always On during OS patching. Any minor mistakes for Always On Availability Group (AG) failover during OS patching can cause huge downtime. And this is because the database can go to recovery pending state and application will not be able to connect.
Therefore it is very critical to follow proper steps. In addition to this, the article will help non DBAs or accidental DBAs as well.
One of the main idea behind implementing SQL Server Always On is to minimize downtime during any kind of patching activity.
Steps to Follow in SQL Server Always On During OS Patching
- Backup Confirmation:
Please make sure we have good full/diff backups of all the databases. This is to avoid any unwanted situation. Like in worst case you may need to restore from database backup and re-establish Always On. - Validate Synchronization State: Make sure that synchronization state for all databases is SYNCHRONIZED and Failover Readiness shows No Data Loss in Availability Group (AG) Dashboard.
- Right Click on AG from Primary Server and go to Dashboard
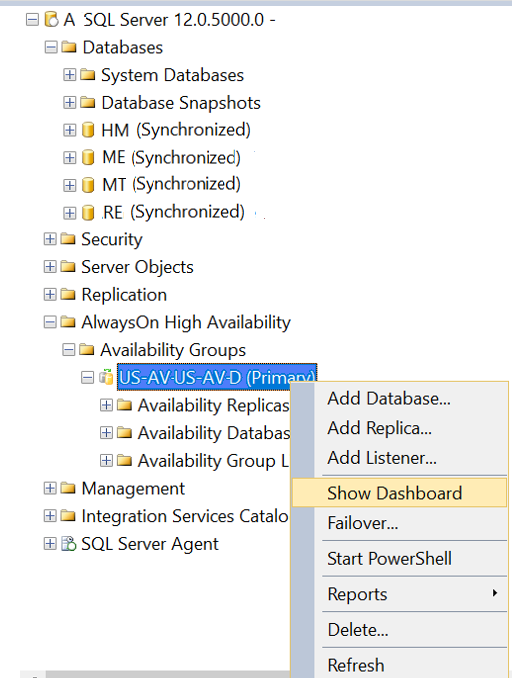
- You need to check Synchronization State is Synchronized, and Failover Readiness is No Data Loss.
Also make sure there is no error shows in the AG Dashboard as shown below:
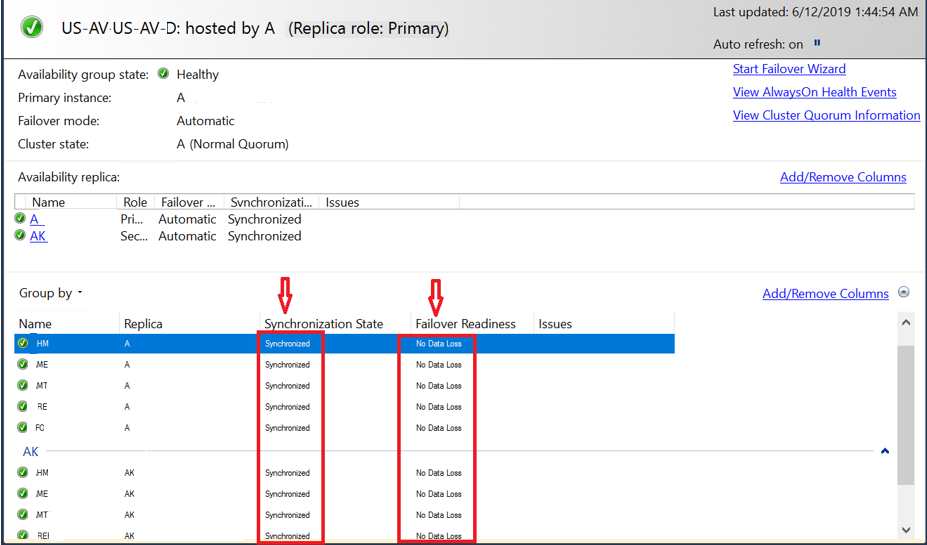
The above step is for you to validate that you do not loose any data during failover of Always On AG. Other synchronization State can be “Synchronizing” and Failover Readiness is “Data Loss”. In that case you got to do some work before failover.
3. Change Failover Mode:
Change the failover mode of AG group to manual. This step is to make sure to have control during Node reboot after patching. Obviously you don’t want the AG to failover automatically during the activity.